The howto has two parts: information on transforms and information on writing to files.
FileTransform.py in which you'll write two
functions. You can test these functions before testing the pig-latin
and rot13 functions you'll write in Transforms.py that
are described below.
You can run the program and it will print the contents of a file to the Eclipse console window. You'll need to transform the data read from a file and print to a file rather than to the console window. Then you'll need to write new transforms for piglatina and rot13. These are described after the Getting Started section below.
Transforms.py as described
below.
The main function transform_file will do three tasks/things by
calling functions: you will write code that helps the second
and third of these tasks.
Each task/phase of the program is described below:
You'll choose a file to transform -- the data directory
that comes with this assignment has three files in it, you can
choose to transform those or other files you have. You may have to
use the file dialog to navigate to the data
directory.
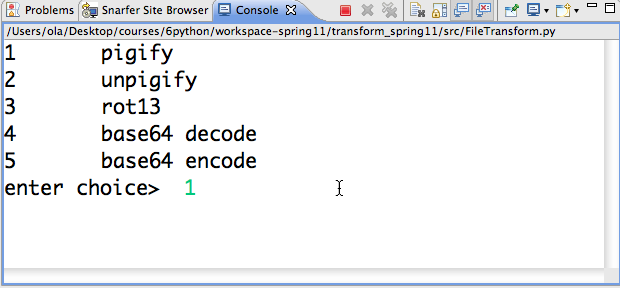
Reading the file creates a list of the lines in the file. Each line is
represented by a list of strings/words on that line. This list
of lists is returned by the function get_words which is
written. The code then prompts the user for a transform by
displaying a text-based menu in the Eclipse console:
This transform should be applied to each word in the file being
transformed. This means you must write code in the function
transform
to create a new list of lists, with each word in the parameter
words
being transformed by applying func. For example, if
the parameter words is the two lines from a file
represented by
the two lists below:
[ ["This", "is", "the", "story"], ["of", "a", "streetcar", "named", "Desire"]]
Then if the parameter func represents piglatin, you'll
write code to return this list:
[ ["is-Thay", "is-way", "e-thay", "ory-stay"], ["of-way", "a-way", "eetcar-stray", "amed-nay", "esire-Day"]]
The code you're given in transform returns a copy of the
list of words. You should modify it to return a transformed copy.
The program then calls write_words with a file open for
writing
and a list of transformed data/words. You must complete
write_words
so that it writes the transformed data to a file.
There's information below on writing to a file, you'll need to test both
the code in FileTransform.py that reads and writes a
file and the code in Transforms.py that does the transforms.
You'll modify the Python module named
Transforms.py. In this module you must
ultimately write functions pigify and
unpigify that each have a single string parameter
and return a string that is either the pig-latin equivalent
(pigify)
or that is reversed from piglatin to normal text
(unpigify). You're given one transform function
named identity that does a no-transform transform leaving
the data unmodified (this was named vanilla in the
original
version of the assignment, name changed on 2/28/2011).
You'll need to test the module yourself, by running code you write to
see that the two functions dealing with piglatin work as
intended. Then you'll add these functions as valid
transforms in FileTransform.py (see below).
My function looks something like this, but the one below doesn't work for every word:
rot13 function. This
function both encodes and decodes a string, so one function
fills two roles. See the rot13 section for
details on this encoding.
You'll need to use FileTransform.py to
test whether your transforms work with files too. This means you'll need
to add your transform functions, e.g.,
Transforms.piglatin to the list of functions in
choose_transform and you'll need to add a
corresponding string so the user can choose the function. These
will be added in the lists funcs and
names respectively.
FileTransform.py. Currently that program uses base64
transforms
and a identity do-nothing transform (the identity
function was named vanilla in the original code). You'll need to add
functions and prompts to the code in choose_transform
so that the transforms you write can be called to transform data
In creating piglatin you will not be concerned with punctuation, so treat every character as either a vowel or not-a-vowel, and punctuation falls into the second category.
| Word | Piglatin Equivalent |
|---|---|
| anchor | anchor-way |
| elegant | elegant-way |
| oasis | oasis-way |
| isthmus | isthmus-way |
| only | only-way |
| Word | Piglatin Equivalent |
|---|---|
| computer | omputer-cay |
| slander | ander-slay |
| spa | a-spay |
| pray | ay-pray |
| yesterday | esterday-yay |
| strident | ident-stray |
| rhythm | ythm-rhay |
| Word | Piglatin Equivalent |
|---|---|
| quiet | iet-quay |
| queue | eue-quay |
| quay | ay-quay |
A few words won't conform to these rules, but the rules should always be used. If a word contains no vowels it should be treated as though it starts with a vowel --- for example "zzz" will be translated to "zzz-way".
It's possible that different words will be transformed to the same piglatin form. For example, "it" is "it-way", but "wit" is also "it-way" using the rules above.
rot13 to use a
(Wikipedia) ROT13 cipher to
encode/decode a string, and then use this to encode
every word in a file.
The function rot13 returns a rotated form
of its string parameter:
To convert a letter character to its ROT13 equivalent we suggest using
these strings, the .find method that returns an
index, and the string indexing operator.
a = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" b = "NOPQRSTUVWXYZABCDEFGHIJKLMnopqrstuvwxyzabcdefghijklm"For example, the letter 'S' in the first string (labeled
a above) is found at index 18. Note that
a.find("S") will evaluate to 18. Then
b[18] represents the encoding for 'S', namely 'F'. You
can reverse the roles of the strings a and
b since the ROT13 cipher is symmetric.
There are other ways to do the ROT13 cipher using the functions
chr, ord and the % operator, but the
approach suggested by using indexing and the strings above
is much easier to get working.
You can identify non-letters by using the return value of the string
find method which will be -1 for non-letters. Alternatively
you can use the Python
string module to identify letters. For example, the
code below generates the output that follows it.
1
2
3
!
,
#
Note that you must import the string module to use its
functions and constants,
see the Python string docs for full information on the module.
.write method which takes a string as a parameter,
two uses shown below: