When you submit your work, follow the instructions on the submission workflow page scrupulously for full credit.
Instead of handing out sample exams in preparation for the midterm and final, homework assignments include several problems that are marked Exam Style . These are problems whose format and contents are similar to those in the exams, and are graded like the other problems. Please use these problems as examples of what may come up in an exam.
As a further exercise in preparation for exams, you may want to think of other plausible problems with a similar style. If you collect these problems in a separate notebook as the course progresses, you will have a useful sample you can use to rehearse for the exams.
Is this assignment properly formatted in the PDF submission, and did you tell Gradescope accurately where each answer is?
This question requires no explicit answer from you, and no space is provided for an answer in the template file.
However, the rubric entry for this problem in Gradescope will be used to decuct points for poor formatting of the assignment (PDF is not readable, code or text is clipped, math is not typeset, ...) and for incorrect indications in Gradescope for the location of each answer.
Sorry we have to do this, but poor formatting and bad answer links in Gradescope make our grading much harder.
Consider the following matrices:
$$ A = \left[\begin{array}{rrr} 1 & 0 & 1 \\ 0 & 1 & 0 \end{array}\right] \;\;\;\;\;\; B = \frac{1}{2} \left[\begin{array}{rrr} \sqrt{3} & 0 & 1 \\ 0 & 2 & 0 \end{array}\right] \;\;\;\;\;\; C = \frac{\sqrt{2}}{2} \left[\begin{array}{rr} 1 & 1 \\ -1 & 1 \end{array}\right] \;\;\;\;\;\; D = \frac{1}{2}\left[\begin{array}{rrrr} 1 & -1 & 1 & 1 \end{array}\right] \;\;\;\;\;\; $$and their transposes $A^T$, $B^T$, $C^T$, $D^T$.
List all and only the orthogonal matrices among these eight matrices according to the definition of orthogonality given in the class notes.
Let $V$ be an orthogonal matrix with 3 rows and 2 columns. We saw in class that this implies that $V$ has a left inverse, that is,
$$ V^TV = I_2 $$where $I_2$ denotes the $2\times 2$ matrix.
We also saw that $V$ cannot have a right inverse, because such a mtrix would have to be the solution $X$ to the system
$$ VX = I_3 $$where $X$ is $2\times 3$ and $I_3$ is the $3\times 3$ identity matrix. The solution $X$ cannot exist because $V$ has rank 2 and therefore the product $VX$ cannot have a rank greater than 2, while $I_3$ has rank 3.
Carlo now argues that perhaps $V$ has a "pseudo right inverse," that is, a $2\times 2$ matrix $Y$ such that
$$ VY = I_{32} \;\;\;\text{where}\;\;\; I_{32} = \left[\begin{array}{cc} 1 & 0\\ 0 & 1\\ 0 & 0 \end{array}\right] $$is the "$3\times 2$ identity."
Carlo's argument is that since $V$ is orthogonal and has a left inverse $V^T$, we can multiply both sides of the equation above by $V^T$ from the left to obtain
$$ V^TVY = V^T I_{32} $$that is,
$$ Y = V^T I_{32} $$because $V^TV = I_2$.
If
$$ V = \left[\begin{array}{cc} v_{11} & v_{12} \\ v_{21} & v_{22} \\ v_{31} & v_{32} \end{array}\right] $$then direct calculation shows that
$$ Y = \left[\begin{array}{cc} v_{11} & v_{21} \\ v_{12} & v_{22} \end{array}\right] \;. $$In other words, the "pseudo right inverse" is formed by the first two columns of $V^T$.
(a) Compute $Y$ for the orthogonal matrix
$$ V = \frac{1}{2} \left[\begin{array}{rr} \sqrt{3} & 0 \\ 1 & 0 \\ 0 & 2 \end{array}\right] $$(b) Compute the exact value of $VY$. As you will see, this is not equal to $I_{32}$, and this contradicts Carlo's assertion.
(c) Explain as clearly as you can why Carlo's argument is wrong.
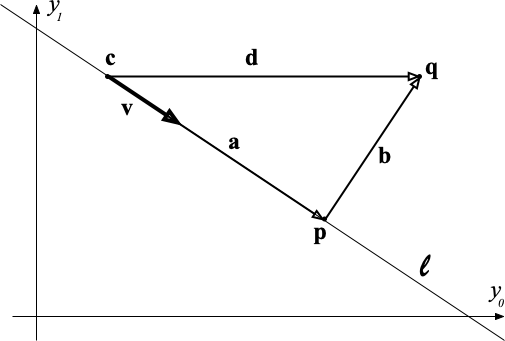
The problems in this part refer to the situation shown in the figure below. The point $\mathbf{c}$ is an arbitrary point on the line $\ell$ on the plane, and the vector $\mathbf{v}$ is an arbitrary but nonzero vector parallel to $\ell$.
The point $\mathbf{q}$ is an arbitrary point on the plane and the point $\mathbf{p}$ is the point on $\ell$ that is closest to $\mathbf{q}$ in Euclidean distance. The point $\mathbf{p}$ is called the projection of $\mathbf{q}$ onto $\ell$.
In some problems below, but not all, the line $\ell$ goes through the origin and $\mathbf{c}$ is then set to be the origin itself, for convenience. Also, in some problems below, but not all, the vector $\mathbf{v}$ has unit norm.
A line $\ell$ on the plane has parametric equation
$$ \mathbf{y}(\alpha) = \mathbf{c} + \mathbf{v} \alpha $$where $\mathbf{c}, \mathbf{v}$ are fixed vectors in $\mathbb{R}^2$, $\mathbf{v}$ is not the zero vector, and $\alpha$ is real-valued variable. The vectors $\mathbf{c}$ and $\mathbf{v}$ are not unique given $\ell$.
This equation means that $\ell$ is the set of all points $\mathbf{y}(\alpha)$ obtained as $\alpha$ varies in $\mathbb{R}$.
As mentioned above, given a point $\mathbf{q}$ on the plane, the projection of $\mathbf{q}$ onto $\ell$ is the point $\mathbf{p}$ of $\ell$ that is closest to $\mathbf{q}$ in Euclidean distance.
Use calculus to derive an expression for the vector $\mathbf{p}$ as functions of $\mathbf{c}$, $\mathbf{v}$, $\mathbf{q}$. Show your derivation and use vector notation throughout (that is, do not "spell out" vectors in terms of their coordinates).
Here, "use calculus" means to use standard methods based on derivatives to find the minimum of a function. This requirement rules out using intuitions such as "this is perpendicular to that." While these intuitions may be correct, they need to be proven, so we cannot rely on them. There are proofs with a geometric flavor, but you are asked for one based on differentiation and minimization.
Consider the expression for $\mathbf{p}$ you found in problem 1.2 in the special case in which the line $\ell$ passes through the origin and $\mathbf{c}$ is the zero vector. In this case, it turns out that you can write
$$ \mathbf{p} = P \mathbf{q}\;. $$Write an expression for the matrix $P$, which is called the projection matrix onto $\ell$ (where it is assumed that $\ell$ goes through the origin).
Prove that the projection matrix $P$ you found above is symmetric, has rank 1, and is idempotent. A matrix $P$ is idempotent if
$$ P = P^2 $$(and therefore $P = P^k$ for every positive integer $k$).
Give the simplest possible expression for $P$ in the special case in which $\mathbf{v}$ is a unit vector.
Suppose that you are given $n$ points $\mathbf{q}_0,\ldots, \mathbf{q}_{n-1}$ on the plane arranged into the rows of an $n\times 2$ matrix $Q$:
$$ Q = \left[\begin{array}{c} \mathbf{q}_0^T \\ \vdots \\ \mathbf{q}_{n-1}^T \end{array}\right] \;. $$If you suspect that the points are not too far from being aligned, it makes sense to look for a line that fits the points as well as possible. Using linear regression would write the line in the form
$$ a y_0 + b = y_1 $$where a point $\mathbf{y}$ on the plane has coordinates $y_0, y_1$, and then find coefficients $a$ and $b$ that minimize the residual of the following over-constrained linear system of $n$ equations in 2 unknowns:
$$ \left[\begin{array}{cc} \boldsymbol{\gamma}_0 & \mathbf{1} \end{array}\right] \left[\begin{array}{cc}a\\b \end{array}\right] = \boldsymbol{\gamma}_1 \;. $$In this expression, $\boldsymbol{\gamma}_0$ and $\boldsymbol{\gamma}_1$ are the columns of $Q$ and $\mathbf{1}$ is a column vector of $n$ ones.
There are at least two limitations to this approach:
A more general approach is Principal Component Analysis (PCA), which addresses the following problem:
Given $n$ points in $\mathbb{R}^d$ as the rows of an $n\times d$ matrix $Q$ and an integer dimension $e$ with $0 < e < d$, fit an $e$-dimensional affine subspace $\cal{A}$ of $\mathbb{R}^d$ to the points in $Q$.
An $e$-dimensional affine subspace $\cal{A}$ of $\mathbb{R}^d$ can be represented in parametric form as follows:
$$ \mathbf{y} = \mathbf{c} + V \boldsymbol{\alpha} $$where
Thus, all points in $\cal{A}$ are equal to $\mathbf{c}$ plus a linear combination (with coefficients in $\boldsymbol{\alpha}$) of the columns of $V$, which form an orthonormal basis for $\cal{A}$.
Please spend a minute to verify that when $d = 2$ and $e = 1$ the affine space $\cal{A}$ is the same as the line $\ell$ in Part 2 of this assignment if the vector $\mathbf{v}$ defined there has unit norm. Also note that even if $\mathbf{y}$ happens to be on an $e$-dimensional space, we still need $d$ coordinates for it when we express it in the reference system for $\mathbb{R}^d$.
An algorithm for computing $\mathbf{c}$ and $V$, that is for fitting an affine $e$-dimensional space to a set of $d$-dimensional points, is as follows (given without proof).
The point $\mathbf{c}$ is the centroid of all the points in $Q$:
$$ \mathbf{c} = \frac{1}{n} \sum_{i=0}^{n-1} \mathbf{q}_i \;. $$Subtract the centroid from every row of $Q$ to obtain the matrix of centered points
$$ \tilde{Q} = Q - \mathbf{1} \mathbf{c}^T $$where $\mathbf{1}$ is a column vector of $n$ ones. (Of course, in Python you would just say $\tilde{Q} = Q - \mathbf{c}$ because of the broadcasting rules of numpy).
Let
$$ \tilde{Q} = \tilde{U} \tilde{\Sigma} \tilde{V}^T $$be the SVD of $\tilde{Q}$. Then, an orthonormal basis for the affine space $\cal{A}$ is given by the matrix
$$ V = \tilde{V}[:,\ :\!e] $$made of the first $e$ columns of $V$.
The points $\mathbf{c}$ and matrix $V$ computed by PCA are the elements of a parametric representation of the affine $e$-dimensional space that best fits the points in $Q$:
$$ \mathbf{y}(\boldsymbol{\alpha}) = \mathbf{c} + V\boldsymbol{\alpha} $$where $\alpha$ is an $e$-dimensional vector of parameters.
Compare this equation with the parametric equation of the line $\ell$ in Part 2 of this assignment. However, in this new equation, $\mathbf{c}$ and $V$ are no longer arbitrary: $\mathbf{c}$ is the centroid of the points in $Q$ and $V$ is orthonormal.
Just as you did in Part 2, but now in more dimensions, if you have $\mathbf{c}$ and $V$ you can also find the projection $\mathbf{p}$ of a point $\mathbf{q}\in\mathbb{R}^d$ as follows:
$$ \mathbf{p} = \mathbf{c} + VV^T (\mathbf{q} - \mathbf{c}) \;. $$Incidentally, this may be a good time to check that the results you found in Part 2 are consistent with this equation when $d=2$, $e=1$, and $\|\mathbf{v}\| = 1$.
You will need some utility functions and some data for this Part. To this end, run the two code cells below.
import urllib.request
import ssl
from os import path as osp
import pickle
import shutil
def retrieve(file_name, semester='spring23', homework=4):
if osp.exists(file_name):
print('Using previously downloaded file {}'.format(file_name))
else:
context = ssl._create_unverified_context()
fmt = 'https://www2.cs.duke.edu/courses/{}/compsci527/homework/{}/{}'
url = fmt.format(semester, homework, file_name)
with urllib.request.urlopen(url, context=context) as response:
with open(file_name, 'wb') as file:
shutil.copyfileobj(response, file)
print('Downloaded file {}'.format(file_name))
retrieve('hw4_utils.py')
mnist_file = 'mnist_subset.pkl'
retrieve(mnist_file)
with open(mnist_file, 'rb') as file:
digits = pickle.load(file)
Downloaded file hw4_utils.py Downloaded file mnist_subset.pkl
Write a function with header
def pca(q, e):
that takes an $n\times d$ numpy array q of floating point numbers and an integer e between 0 and $d$ exclusive and returns a dictionary with keys 'centroid' and 'basis'. The values corresponding to these keys are the centroid $\mathbf{c}$ (a numpy vector with $d$ entries) and the $d\times e$ matrix $V$ of the PCA of q.
Then test your code by fitting a line to a set of points on the plane. To this end, call
from hw4_utils import noisy_plane_points
q0, c0, v0, rect = noisy_plane_points(30, sigma=0.1)
The values returned by noisy_plane_points are as follows:
q0 representing 30 points on the plane. These are noisy versions of points that, in the absence of noise, would be on a vertical line. In this way, you can verify that PCA can handle vertical lines with no problem.c0 and v0 (both numpy 2-vectors) that represent the ideal line.rect with keys left, right, bottom, top that specify the sides of a rectangular box to be used to display the points. Each value is a coordinate.Then, call your pca function with appropriate parameters to compute the PCA of q0, so that the PCA represents a line.
Finally, make a figure that displays the following:
pca in blue.Make the dots large enough to be visible, especially the blue ones.
To draw the lines, you can say
from hw4_utils import plot_line
and then
plot_line(c0, v0, rect)
for the ideal line, and a similar command for the line found by PCA.
sklearn.decomposition.PCA. Instead, used numpy.linalg.svd.numpy.linalg.svd returns the transpose of $V$, not $V$ itself. Also you don't need $U$ or $\Sigma$.assert statement that checks that e is within proper bounds.plot_line does not make a figure or call plt.show() or plt.draw(). That call is up to you.rect.from hw4_utils import box_aspect
aspect = box_aspect(rect)
Besides fitting affine subspaces, another common use of PCA is data compression. To understand this concept, let us go back to the projection equation:
$$ \mathbf{p} = \mathbf{c} + VV^T (\mathbf{q} - \mathbf{c}) \;. $$We can break down this equation into two steps:
$$ \begin{eqnarray*} \text{Compression:} & \phantom{wide} & \boldsymbol{\alpha} = V^T (\mathbf{q} - \mathbf{c}) \\ \text{Embedding:} & & \mathbf{p} = \mathbf{c} + V\boldsymbol{\alpha} \end{eqnarray*} $$which we can understand intuitively as follows.
Note that $\mathbf{q}$, $\mathbf{c}$, and $\mathbf{p}$ are in $\mathbb{R}^d$ (the large space) while $\boldsymbol{\alpha}$ is in $\mathbb{R}^e$ (the small space).
Specifically, the compression equation above shows that entry $\alpha_j$ of $\boldsymbol{\alpha}$ is the inner product of $\tilde{\mathbf{q}} = \mathbf{q} - \mathbf{c}$ with column $j$ of $V$ (or row $j$ of $V^T$). That is, $\alpha_j$ is the $j$-th coordinate of $\tilde{\mathbf{q}}$ in the orthonormal reference frame represented by the columns of $V$.
In this sense, this mapping compresses a $d$-dimensional point $\mathbf{q}$ to an approximate representation $\boldsymbol{\alpha}$ of it in the lower-dimensional space $\cal{A}$ of dimension $e$, for which a parametric representation $(\mathbf{c}, V)$ is known.
For instance, in Problem 3.1, the blue points are approximations to the red points. They have two coordinates ($\mathbf{p}$) because they are points on the plane. However, if we know that they are on the blue line, for which we have computed a parametric representation, a single number per point ($\alpha$) is sufficient.
The vector of coordinates $\boldsymbol{\alpha}$ represents the projection $\mathbf{p}$ of $\mathbf{q}$ onto $\cal{A}$, not $\mathbf{q}$ itself. This is why $\boldsymbol{\alpha}$ is an approximate representation.
That projection can be expressed in the original reference system for $\mathbb{R}^d$ (the large space) by the change of basis given in the embedding equation. We do not call this transformation a "decompression" because the final vector $\mathbf{p}$ is not equal to $\mathbf{q}$ but rather to the projection of $\mathbf{q}$ onto $\cal{A}$.
Therefore, $\mathbf{p}$ is merely an approximation to $\mathbf{q}$, and the approximation is good only to the extent that $\mathbf{q}$ is not too far from $\cal{A}$.
For instance, in Problem 3.1, the blue dots are good approximations of the red dots only to the extent that the red dots are approximately aligned to each other (and therefore to the PCA line) to begin with.
An extreme version of compression arises when $d$ is, say, an MNIST digit image with $d = 784$ dimensions (recall that MNIST images have $28\times28$ pixels) and $e = 2$. Then, the vectors $\alpha$ have two coordinates each, and can be plotted on the plane to give a very crude appoximation of the relative arrangement of the original $784$-dimensional points. Let us see how this works.
In the preamble to this part of the assignment, you ran a code cell that retrieved a small portion of the MNIST data set and loaded it into the dictionary digits.
The value for digits['x'] is an numpy floating-point array $Q$ of shape $n\times d = 2000\times 784$. Each row of $Q$ is a flattened MNIST image. As usual, digit['y'] is a numpy array of $n$ integers that specify the true label for each image.
Write a function with header
def compress(q, space):
that applies the compression operation described above to the rows of q (an $n\times d$ numpy array) and produces the coordinates alpha (a $n\times e$ numpy array).
The argument space is a PCA dictionary returned by your pca function.
Use your pca function to compute the PCA of digits['x'] for $e = 2$ dimensions and use the result to compress the array digits['x'] itself.
Make a plot of all the alpha points, one dot per point. Each dot should have one of ten distinct colors that denotes what digit that point represents (that is, its true label). Your plot should include a legend that shows which color corresponds to which digit.
Your picture will show a rather disorganized jumble of points, although some of the digits appear to cluster together. Answer the following questions:
Which digit forms the tightest and most well-separated cluster in your plot?
Most of the dots for different digits seem to be interspersed with each other. Why is your plot misleading in this regard? That is, why is it still possible that the actual data form more well-separated clusters than the plot seems to suggest?
Since the points $\mathbf{q}_i$ are in the rows of $Q$, we rewrite the compression and embedding (for later reference) equations by transposing them and collecting them into matrix form:
$$ \begin{eqnarray*} \text{Compression:} & \phantom{wide} & A = (Q - \mathbf{1}\mathbf{c}^T) V \\ \text{Embedding:} & & P = \mathbf{1} \mathbf{c}^T + A V^T \end{eqnarray*} $$where $\mathbf{1}$ is a vector of $n$ ones. In Python, you can essentially ignore this vector, given standard numpy broadcasting rules. Remember to use matrix multiplication (@) where appropriate.
We now explore how well the compressed images above approximate the true ones.
Write a function with header
def embed(alpha, space):
that implements the embedding transformation. The argument alpha is the array output by your compress function and space has the same meaning as before.
Then select one image and its corresponding label out of digits for each label in $\{0, \ldots, 9\}$ (your choice) and use these ten digit samples to make a figure with a $2\times 10$ grid of subplots. Subplot (1, k) has the true digit image for label k from your sample, with the true label as title. Subplot (2, k) has the digit image reconstructed by embed.
Some digit approximations are recognizable, while others are more confused. This is not surprising, since we are compressing 784 dimensions down to 2. To visualize where the confusion comes from, note that the embedding equation
$$ \mathbf{p} = \mathbf{c} + V\boldsymbol{\alpha} $$for this example can be rewritten as follows:
$$ \mathbf{p} = \mathbf{c} + \alpha_0 \mathbf{v}_0 + \alpha_1 \mathbf{v}_1 $$where $\mathbf{v}_0$ and $\mathbf{v}_1$ are the two columns of $V$.
Thus, the approximate image $\mathbf{p}$ is the centroid $\mathbf{c}$ of all the images plus a linear combination of two "singular images" $\mathbf{v}_0$ and $\mathbf{v}_1$.
All these vectors have 784 entries, so they can all be reshaped into $28\times 28$ images.
Display the vectors $\mathbf{c}$, $\mathbf{v}_0$, and $\mathbf{v}_1$ as $28\times 28$ images in a figure with a 1 by 3 grid of subplots. Put a title above each image.
signed_image imported from hw4_utils to get a color image. In this image, positive values are left as is (gray) and negative values are shown in red.Redraw the figure you made in Problem 3.3, but using $e=30$ instead of $e=2$. Of course, projecting to a larger subspace reduces the approximation error.
Conceptually, the aperture problem in computer vision is the fact that the motion between two images can be determined through local analysis at a given point only if the image texture in the near vicinity of that point is rich enough.
Mathematically, in a differential description of the relation between image intensities and motion, the aperture problem refers to the fact that the Brightness Change Constraint Equation (BCCE)
$$ \mathbf{u}^T \nabla_{\mathbf{x}} I + I_t = 0 $$is a single scalar equation in the two components of the velocity vector $\mathbf{u}$, and therefore cannot constrain $\mathbf{u}$ uniquely.
If on the other hand motion is described as a finite displacement $\mathbf{d}$, then the aperture problem refers to the fact that at a single point $\mathbf{x}$ there may be multiple connected local minima of the image residual
$$ \ell(\mathbf{x}, \mathbf{d}) = [J(\mathbf{x} + \mathbf{d}) - I(\mathbf{x})]^2 $$as a function of $\mathbf{d}$. Specifically, the two scalar equations provided by the vector normal equation
$$ \nabla_{\mathbf{d}}\ell(\mathbf{x}, \mathbf{d}) = \mathbf{0} $$may be linearly dependent.
Because of the aperture problem, the differential version is typically formulated as a global problem in which the motion field $\mathbf{u}(\mathbf{x})$ is required to be smooth, and the finite-displacement version is typically formulated under the assumption that the displacement vector $\mathbf{d}$ is constant in a small window around $\mathbf{x}$. If image texture is rich enough, these additional assumptions provide new constraints that pin down a solution.
This part of this assignment explores different facets of the aperture problem. All images considered here are black-and-white.
If the spatial gradient $\nabla_\mathbf{x} I$ of image intensity $I$ is nonzero at a certain point $\mathbf{x}$ and the unit vector along that gradient is denoted as
$$ \mathbf{g} = \frac{\nabla_\mathbf{x} I}{\|\nabla_\mathbf{x} I\|} $$then the normal component of the image motion $\mathbf{u}$ at $\mathbf{x}$ is the velocity
$$ v = \mathbf{g}^T \mathbf{u} \;. $$Give the values of $\mathbf{u}_0$ and $\mathbf{b}$ in a parametric representation
$$ \mathbf{u} = \mathbf{u}_0 + \alpha \mathbf{b} $$of the line of all motions $\mathbf{u}$ that are consistent with a given normal component $v$ and unit image gradient $\mathbf{g}$. In your representation, $\mathbf{u}_0$ should have the smallest norm possible and $\mathbf{b}$ must be one of two possible unit vectors.
A certain telescope with an electronic image sensor is pointed at a star in the night sky, and the image of the star is at the origin of a reference system on the sensor. The telescope is slightly out of focus, so the irradiance produced by the light from the star on the sensor plane is an isotropic Gaussian function of the position $\mathbf{x}$ on the sensor:
$$ I(\mathbf{x}) = e^{-\frac{\|\mathbf{x}\|^2}{\sigma^2}} $$for $\sigma = 7$ millimeters.
Two images $I_0$ and $I_1$ are taken a minute apart, and as a result the peak of the star image and the Gaussian around it translates from position $(0, 0)$ to a new position $\mathbf{d}$ on the sensor.
The images turn out to be saturated (too bright), and therefore measurements of the position of the peak of the Gaussian are unreliable. Instead, measurements are taken at positions away from the peak, where both images are better exposed, and these measurements reveal the following:
Give the exact numerical value of the displacement $\mathbf{d}$ in millimeters. Show your derivation.
The figure below shows six different $31\times 31$ windows in the two images fauci_0.png and fauci_1.png retrieved and loaded in the code cell below. Each window has a name, and the names and center coordinates of the windows are stored in the dictionary points imported from hw4_utils below. The variable win_h_size defined below is bound to 15, which is half the window size (excluding the midpoint).

import skimage as sk
import numpy as np
names = ['fauci_0.png', 'fauci_1.png']
for name in names:
retrieve(name)
images = [sk.io.imread(name) for name in names]
from hw4_utils import points
win_half_size = 15
Downloaded file fauci_0.png Downloaded file fauci_1.png
You can compute the gradient of the image images[0] as follows, using a Gaussian kernel with a half-width of 5 pixels:
from hw4_utils import gradient
gauss_half_size = 5
grad_r, grad_c = gradient(images[0], gauss_half_size)
The two numpy arrays grad_r and grad_c are the vertical and horizontal components of the gradient, and have the same shape as images[0] and images[1].
You can also make a $31\times 31$ array of Gaussian weights as follows:
from hw4_utils import gauss
gauss_vector = gauss(win_half_size)[0]
gauss_weights = np.outer(gauss_vector, gauss_vector)
Write a function with header
def gramian(gr, gc, p, w):
to be called as follows:
a = gramian(grad_r, grad_c, point, gauss_weights)
where all variables other than point were defined above. The variable point is one of the values in the dictionary points imported above.
Your function gramian should return a numpy array of floats representing the $2\times 2$ matrix $A$ defined in equation (15) of the class notes on image motion.
Then write code that produces a printout and two figures.
points, the printout should contain a single line with the name of that point and the eigenvalues $\lambda$s (use np.linalg.eigvals) of the corresponding matrix $A$ sorted in decreasing order.points, produced with a plt.text instruction. The string is that point's name and the center of the string should be at coordinates $\log(\lambda_0), \log(\lambda_1)$ of the plot. Label the axes. Since $\lambda_0 \geq \lambda_1$, all points are under the identity function. For reference, also draw the line for the identity function on the plot, and make sure that the scaling of the two axes is the same (plt.axis('equal')).images[0] centered at the values specified in points. Use plt.imshow with parameters cmap=plt.cm.gray, vmin=0, vmax=255 for proper display. Give each subplot a title with the name of the window (a key from points) and use commands plt.axis('image') and plt.axis('off').The point names in your plot should be arranged roughly in three groups:
jacket close to the bottom left of the plot;background and tie close to each other somewhere near the middle of the plot;Explain this arrangement. Specifically,
What information do $\lambda_0$ and $\lambda_1$ (or equivalently their logarithms) provide about the the distribution of gradients in a window? Specifically, what does this distribution look like, qualitatively and in general, when
Also tie your explanations to the aperture problem.
What explains the division into three groups based on $\lambda_0$ (or equivalently $\log(\lambda_0)$) in terms of the appearance of the specific windows in your last figure? Explain what is going on in each group.
If you are told that Lucas-Kanade can track four of these six windows reliably, which four would you pick, and why? What numerical criterion could you use to tell them apart from the other two?