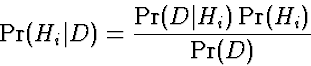If too many Hi models, can't compute the sum. MAP hypothesis is the one that maximizes .If , then
Note that (why?)
is the prior, uniform prior yields maximum likelihood hypothesis.