For data files see the code directory or snarf the
assignment. You are not given any already-written Python code.
You are asked to write several Python modules for this
assignment. Details are here and in the howto
pages.
BookReader.py
BookReader.py |
books.txt
|
ratings.txt
|
Input to
get_data(books,ratings)
|
Format: Autor,Booktitle
|
Format: Rater
Ratings
|
Output from
get_data(books,ratings) |
itlist

Format: [ "Author,Book title", "Author,Book
title", "Author,Book title"...]
|
rdict
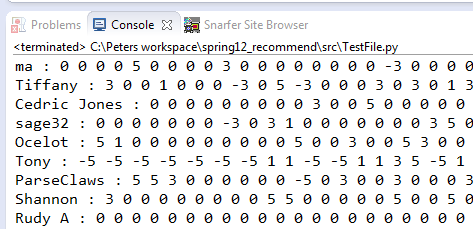
Format: {"Rater":Ratings, "Rater":Ratings,
"Rater":Ratings, ...}
|
MovieReader.py
MovieReader.py
|
movieratings.txt
|
|
Input to
get_data(movieratings)
|
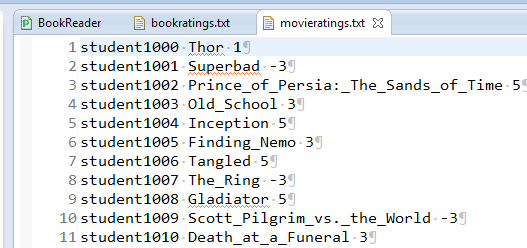
Format: Rater Title Rating
|
|
Output from
get_data(movierationgs)
|
itlist
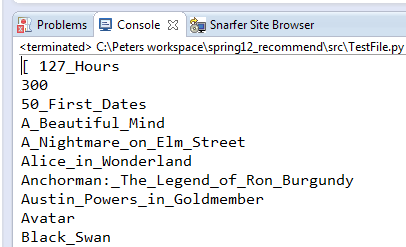
Format: ["Title", "Title", "Title"...]
|
rdict
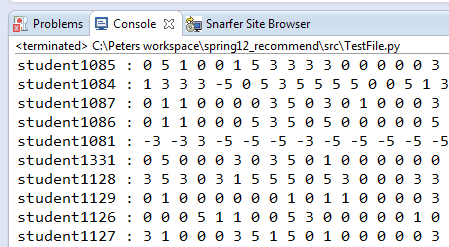
Format: {"rater":ratings, "rater":ratings,
"rater":ratings, ...}
|
Reading Data
Each data-reading module you write has a function get_data
that returns two values: a list and dictionary.
First a toy example about food is shown below. Feel free to use parts of
this code in your module. This module shows how to process a file
that contains data for one rater, the rater's name is the first line of
the file. So a sample data file for this format might look like the
following. This is a contrived example, real examples have
multiple users. In this example all users would need to have
food in the same order so that the ratings in rdict would
be in the same order for multiple users.
Owen Astrachan
vanilla milkshake:5
burrito:4
butterflied leg of lamb:-3
eggplant parmesan:1
Code to process this file:
def get_data(food_file):
ratings = [-5,-3,0,1,3,5]
itlist = []
rdict = {}
f = open(food_file)
rdict[name] = []
name = f.readline() # get name, now ratings
for line in f:
line = line.strip().split(":")
item = line[0]
rating = int(line[1]);
itlist.append(item)
rdict[name].append(rating)
f.close()
return itlist, rdict
The example code above shows a hypothetical module for rating food
for a single rater named Owen Astrachan. The function has a parameter
that's the name of a file storing foods and ratings as shown above.
In a real example the data ratings would be stored in one or more of the files to
be read.
This example shows how to return two values from a function, essentially
returning a tuple.
You're given a file books.txt of 55 books and
a file bookratings.txt of ratings for
each book by 86 students/raters.
The ratings for each student are given as 55 numbers where the ith
number is the rating for the ith book in bookratings.txt.
So if your get_data function is called as shown below:
import BookReader
itlist,rdict = BookReader.get_data("books.txt", "bookratings.txt")
print itlistl[:3]
print "---ratings---"
print rdict["owen"]
You should see output like this which shows that
Owen rated Hitchhiker's Guide with a 3, Watership Down with a 5. and hasn't read The Five
People You Meet in Heaven (more after that too).
Douglas Adams,The Hitchhiker's Guide To The Galaxy
Richard Adams,Watership Down
Mitch Albom,The Five People You Meet in Heaven
---ratings---
3 5 0 0 0 0 5 0 0 3 0 5 3 5 3 3 0 3 5 5 0 0 0 3 0 5 0 0 0 0 3 5 3 0 0 0 0 3 3 0 3 0 5 5 0 0 3 0 0 5 5 0 0 0 0
The file bookratings.txt stores the
name of the rater on one line and the ratings on the next line. So you'll
need to call f.readline() twice: once for the name and once
for the ratings. The readline() function returns an
empty-string when there's nothing to read. This leads to code like this for
the part of BookReader.py that reads the ratings file.
f = open(ratings_file)
while True:
name = f.readline()
if len(name) == 0: # nothing left to read
break
name = name.strip() # get rid of newline char
line = f.readline() # ratings for name
ratings = [int(r) for r in line.split()]
# more code here to associate ratings with name
The ratings for movies are stored in movieratings.txt
in a different format than the book ratings. This file stores more than
22,000 ratings by 453 student-raters for 150 movies. Because the data is sparse,
meaning most students don't rate all 150 movies, you'll need to process/read
the file differently to create and return the requisite dictionary. For
example, in the dictionary each list associated with a student/key must have
150 entries if there are 150 movies (don't hard-code the value of 150,
calculate that based on reading the file).
You'll need to think about how to read this data. There are many ways to
do so, but in your code you won't know the total number of movies until
after you've read the entire file. You'll need to return the list of
movies from get_data, you can create this list using sets
and list functions. You'll either need to read the file twice, or store
the data as its read in some way so you can create the dictionary you'll
return after reading the entire file.
So, you can either read the file twice or store (movie,rating)
tuples or lists for each line read and process these pairs in creating the
dictionary you return. For example, after creating a list of 150 movies
you can find the index of any movie using code like movielist.index("Eclipse")
to find the index of the movie "Eclipse".
You'll need to think about how to read, store, and ultimately return a
list and a dictionary such that rdict[x] is a list of N int
values if there are N movies for each rater x that's a key in the
dictionary returned.
You'll need to include a minimum of three functions in the module Recommender.py
that you write. You'll also need to call these functions and document the
results you get.
-
averages(items,ratings) -- returns a list of tuples
where each tuple includes an item being rated and the average rating for
all those who've rated the item. The list should be sorted so that the
highest rated item is first. Each tuple will contain a string (item) and
a float (average) with the string first.
The parameters are the list of items and the dictionary that are
returned by a reading module's get_data method. In
calculating averages you should not count raters who give a value of 0
meaning "not rated". You should divide by (n+1) where n is the number
of non-zero raters, this ensures that you won't get a division-by-zero
error for an item that no one rates.
-
similarities(name, ratings) -- returns a list of
two-tuples where each tuple contains a rater-name (string) and a
similarity-index (int). The list is sorted with the most-similar rater
first. Similarity should be calculated for the user whose name is a
parameter using dot-products as described below.
THe parameters are a string (the name of a rater) and a dictionary of ratings as
returned from get_data.
The rater whose name is
the parameter should not be evaluated as how similar she is to herself,
i.e., the list returned should have one less element than the number of
elements in ratings since the rater is not judged as similar to himself.
A similarity measure can be calculated by finding the
dot-product of two rating-lists. For example, for the rating
lists [-3,0,5,3] and [-1,3,0,5] the similarity is -3*-1 + 0*3 + 5*0 +
3*5 where each corresponding element of the lists are multiplied and
summed. This yields a similar measure of 3+15 = 18. For the lists
[-3,0,5,3] and [3,0,-3,3] the similarity measure is -3*3 + 0*0 + 5*-3 +
3*3 = -9 + -15 + 9 = -15. The rater with [-1,3,0,5] is closer to
[-3,0,5,3] than is the rater with [3,0,-3,3] since the measures are 18
and -15, respectively. The idea is that two negative or two positive
ratings make users closer than do a negative and a positive rating.
The arithmetic result of summing the corresponding products is
called the dot-product and is actually related to a measure of the angle
between two ratings in a mathematical ratings space.
-
recommended(slist,items,ratings,n) -- returns a
list of recommended items. The parameter items is the list
of items returned by get_data as is the dictionary ratings.
The parameter slist is the list returned by similarities,
and n is a number that indicates how many ratings from slist
should be used.
The idea is to weight the ratings of similar raters more than the
ratings of those with whom you don't agree. Consider these ratings,
for example for a user whose ratings are [5,3,-5].
[1,5,-3]
[5,-3,5]
[1,3,0]
The similarity measures are
1*5 + 5*3 + -3*-5 = 35
5*5 + -3*3 + 5*-5 = -9
1*5 + 3*3 + 0*-5 = 14
So we should weight the first set of ratings most and the second set of
ratings least because of how similar these raters are to us and our
ratings.
We do this by accumulating a weighted sum as follows:
35 * [1,5,-3] = [ 35, 175,-105]
-9 * [5,-3,5] = [-45, 27, -45]
14 * [1,3,0] = [ 14, 42, 0]
--------------------------------
[ 4, 244,-150]
This means that the best choice for us is the second item whose score is
244, the next is the first item whose score is 4, and the
least-recommended is the last item whose score is -150.
The list returned is sorted from most-recommended to least
recommended and is a list of tuples where the first element is the
name of an item and the second element is the score (an int) for that
item. Scores are calculated using n entries from the
list slist, so that if n==1 we use only the closest
rater's ratings and if n==len(slist) we use them all.

