Submit using markov as the assignment name. Submit a README, all .java files, and the Analysis.pdf.
As the assignment writeup explains, you must:
- Part 1: make the provided class
MarkovModelfaster (by writing a new modelMapMarkovModel, not changing the existing model) - Part 2 (A): implement the
WordNgramclass - Part 2 (B): use the
WordNgramclass to create a new, word-based Markov Model.
After you snarf the assignment run MarkovMain using the brute-force Markov generator.
Using the GUI, as shown below, go to the File menu->browse and select a data file, each of which is a lexicon, as the training text. There is a data directory provided when you snarf containing several files you can use as training texts when developing your program.
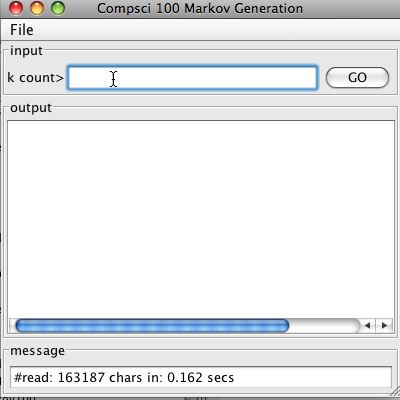
A screen shot of the program just after alice.txt has been loaded. Your computer will probably not load in the file in the exact same time.
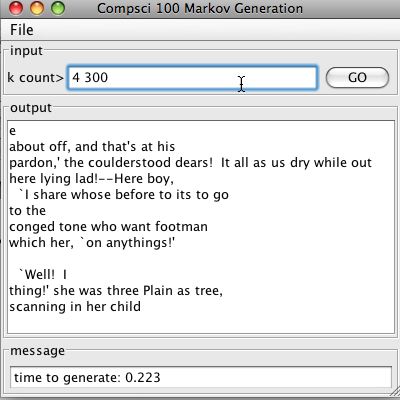
A screen shot after generating 300 random characters using an order-4 Markov model with Alice in Wonderland (alice.txt) as the training text.
Code Overview
The communication between the GUI/View and the model works as follows from the model class perspective:
- The
initializemethod of the model is called with a Scanner from which characters and words are read. The code you have been given already reads all the characters into a string and uses this string to generate characters “at random”, but based on their frequency in an order-k Markov model. - The
processmethod is called when the user presses the GO button or the return/enter key in the text field of the GUI. The convention in this program is that the Object passed toprocessis a String that contains space-separated numbers representing the order k of the Markov model and the number of letters to generate (or number of words). For example, “4 300″ will generate 300 random letters using a 4-gram Markov model. See the existing code for examples. - The model communicates with the view to send a message or an error/message by calling
messageViewswith a String, orshowViewsErrorwith a String, respectively. You can either usemessageViews,this.messageViewsorsuper.messageViewssince the abstract class from which your model inherits contains these methods. - The model sends lots of information to the view by repeatedly calling
updateorsuper.updatewith a String. Theupdatemethod in the views displays a string. To clear the output in the views, callsuper.clear(orclear). To display multiple lines, either construct one string to pass toupdateor callupdaterepeatedly without clearing. - In the code you’re given in MarkovModel the call
this.notifyViews(build.toString());sends the built-up randomly-generated String to the views — see methodbrutein the code. - The code uses a
StringBuilderfor efficiency in constructing the character-by-character randomly-generated text.
Part 1
You’ll implement a class named MapMarkovModel that extends the abstract class AbstractModel. You should use the existing MarkovModel class to get ideas for your new MapMarkovModel class.
You can modify MarkovMain to use your model by simply changing one line.
public static void main(String[] args){
IModel model = new MapMarkovModel(); // this is the only change!
SimpleViewer view = new SimpleViewer("Compsci 100 Markov Generation",
"k count>");
view.setModel(model);
}
Testing Your New Model
As the writeup describes, you’ll use a map instead of re-scanning the text for every randomly-generated character. To test that your code is doing things faster and not differently you can use the same text file and the same markov-model. If you use the same seed in constructing the random number generator used in your new model, you should get the same text, but your code should be faster. You’ll need to time the generation for several text files and several k-orders and record these times with your explanation for them in the Analysis you submit with this assignment.
Debugging Your Code
It’s hard enough to debug code without random effects making it harder. In the MarkovModel class you’re given the Random object used for random-number generation is constructed thusly: myRandom = new Random(1234); Using the seed 1234 to initialize the random-number stream ensures that the same random numbers are generated each time you run the program. Removing 1234 and using new Random()will result in a different set of random numbers, and thus different text, being generated each time you run the program. This is more amusing, but harder to debug. If you use a seed of 1234 in your smart/Map model you should get the same random text as when the brute-force method is used. This will help you debug your program because you can check your results with those of the code you’re given which you can rely on as being correct.
Part 2
Similarly to above, you can modify MarkovMain to use your word model by simply changing one line.
public static void main(String[] args){
IModel model = new WordMarkovModel(); // this is the only change!
SimpleViewer view = new SimpleViewer("Compsci 100 Markov Generation",
"k count>");
view.setModel(model);
}
Remember that for your WordMarkovModel you need to first develop and test the WordNgram.
The WordNgram class
The WordNgram class has been started for you. You can create new constructors or change the constructor given, though the provided constructor will likely be useful. You can also add instance variables in addition to myWords.
You’ll need to ensure that .hashCode, .equals, .compareTo and .toString work properly and efficiently. You’ll probably need to implement additional methods to extract state (words) from aWordNgram object. In my code, for example, I had at least two additional methods to get information about the words that are stored in the private state of a WordNgram object.
To facilitate testing your .equals and .hashcode methods a JUnit testing program is provided. You should use this, and you may want to add more tests to it in testing your implementation.
Testing with JUnit shows that a method passes some test, but the test may not be complete. For example, your code will be able to pass the the tests for .hashCode without ensuring that objects that are equal yield the same hash-value. That should be the case, but it’s not tested in the JUnit test suite you’re given.
Using JUnit
To test your WordNgram class you’re given testing code. This code tests individual methods in your class, these tests are called unit tests and so you need to use the standard JUnit unit-testing library with the WordNgramTest.java file to test your implementation.
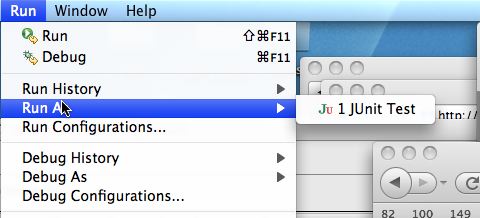
To choose Run as JUnit test first use the Run As option in the Run menu as shonw on the left below. You have to select the JUnit option as shown on the right below. Most of you will have that as the only option.
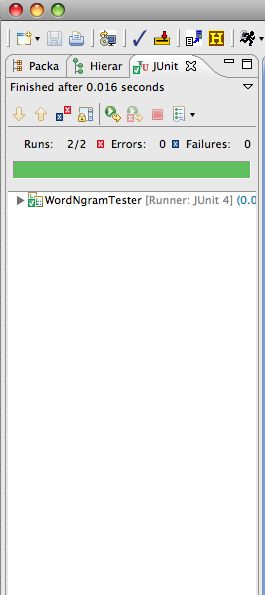
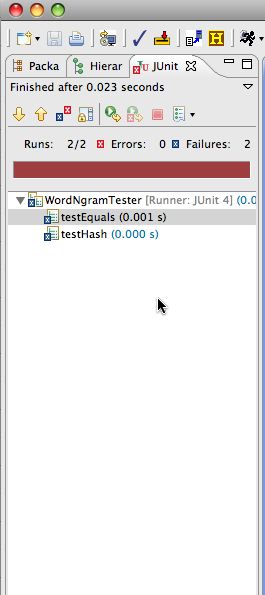
There are two tests inWordNgramTest.java: one for the correctness of .equals and one for the “performance” of the .hashCode method.
If the JUnit tests pass, you’ll get all green as shown on the left below. Otherwise you’ll get red — on the right below — and an indication of the first test to fail. Fix that, go on to more tests. The red was obtained from the code you’re given. You’ll work to make the testing all green.
 |
 |
The WordMarkovModel class
You’ll implement a class named WordMarkovModel that extends the abstract class AbstractModelclass. This should be very similar to the MapMarkovModel class you wrote, but this class uses words rather than characters.
A sequence of characters was stored as a String in the code for character-oriented Markov models. For this program you’ll use ArrayLists (or arrays) of Strings to represent sequences of words used in the model.
The idea is that you’ll use 4-words rather than 4-characters in predicting/generating the next word in an order-4 word based Markov Model. You’ll need to construct the map-basedWordMarkovModel and implement its methods so that instead of generating 100 characters at random it generates 100 words at random (but based on the training text it reads).
To get all words from a String use the String split method which returns an array. The regular expression "\\s+" represents any whitespace, which is exactly what you want to get all the words in file/string.
String[] words = myString.split(“\\s+”); Using this array of words, or a wrap-around-version of it as was the case with characters in the character-based model, you’ll construct a map in which each key, a WordNgram object, is mapped to a list of WordNgram objects — specifically the n-grams that follow it in the training text. This is exactly what your MapMarkovModel did, but it mapped a String to a list of Strings. Each String represented a sequence of k-characters. In this new model, each WordNgram represents a sequence of k-words. The concept is the same.
Comparing Words and Strings in the Different Models
In the new WordMarkovModel code you write you’ll conceptually replace Strings in the map with WordNgrams. In the code you wrote for maps and strings, calls to .substring will be replaced by calls to new WordNgram. This is because .substring creates a new String from parts of another and returns the new String. In the WordMarkovModel code you must create a new WordNgram from the array of strings, so that each key in the word-map, created by calling new, corresponds to a string created in your original program created by calling substring.
Things to be Careful Of
A few things students often mess up in this assignment:
- Your faster map-based character MarkovModel should generate exactly the same text as the brute force method, given the same datafile and k value. Oftentimes there can be a problem that will make the code not select the first word in the same way and so they texts will be different. Test and make sure your code matches.
- Your Map should not be recomputed if the k value is not changed
- Make sure your WordNGram passes all the unit tests
- Make sure you answer all the questions in the analysis